Walk-through on setting up a quick test lab for PySpark
Many thanks to David Jennings’ article and mccarroll.net’s blog that got me started.
$ cd /opt $ wget http://www.apache.org/dyn/closer.lua/spark/spark-1.6.2/spark-1.6.2-bin-hadoop2.6.tgz $ tar xvzf spark-1.6.2-bin-hadoop2.6.tgz $ ln -s /opt/spark-1.6.2-bin-hadoop2.6 spark-latest
Turn the default logging level down:
$ cd /opt/spark-latest/conf $ cp log4j.properties.template log4j.properties $ nano log4j.properties
Change:
log4j.rootCategory=INFO, console
To:
log4j.rootCategory=WARN, console
Install Jupyter (This project used to be called IPython):
$ pip3.5 install jupyter
*** NOTE: I’m installing on CentOS 7 with the ISUS python3.5u & python35u-pip package installed (see my blog post here)
Now edit your ~/.bash_profile:
$ cd ~ $ nano .bash_profile
It should look something like this when you are done (you may have other entries/exports from other applications):
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
export SPARK_HOME=/opt/spark-latest
export PYSPARK_PYTHON=python3.5
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --NotebookApp.open_browser=False --NotebookApp.ip='*' --NotebookApp.port=8880"
PATH=$PATH:$HOME/bin:$SPARK_HOME/bin
export PATH
Now logout and login or re-read your profile within your session:
$ source .bash_profile
For the fun part! Change directory to somewhere you would like to run your Jupyter notebook and download some great poetry (This is important as any files you create will be saved in this dir, also some more instructions, if you run into trouble, can be found here):
$ mkdir jupyter-notebooks $ cd jupyter-notebooks/ $ wget http://ocw.mit.edu/ans7870/6/6.006/s08/lecturenotes/files/t8.shakespeare.txt $ mv t8.shakespeare.txt shakespeare.txt $ pyspark
PySpark should automatically start Jupyter and you should get console output like this:
[W 21:59:04.020 NotebookApp] WARNING: The notebook server is listening on all IP addresses and not using encryption. This is not recommended. [W 21:59:04.020 NotebookApp] WARNING: The notebook server is listening on all IP addresses and not using authentication. This is highly insecure and not recommended. [I 21:59:04.025 NotebookApp] Serving notebooks from local directory: /root/jupyter-notebooks [I 21:59:04.026 NotebookApp] 0 active kernels [I 21:59:04.026 NotebookApp] The Jupyter Notebook is running at: http://[all ip addresses on your system]:8880/ [I 21:59:04.026 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
If all goes well, open a web browser and head to http://<<your-server’s-ip>>:8880/ and you should see something close to this:
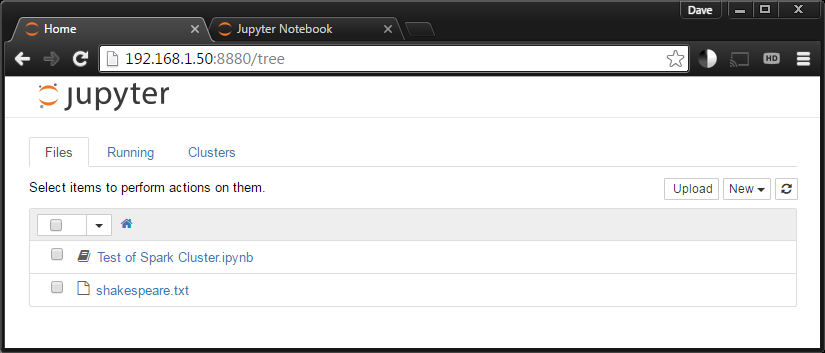
Select the “New” dropdown on the right and click under Notebooks “Python 3”.
***NOTE: You can rename your notebook by clicking the title at the top of the page by the Jupyter logo (Where I have the title, “Test of Spark Cluster” below).
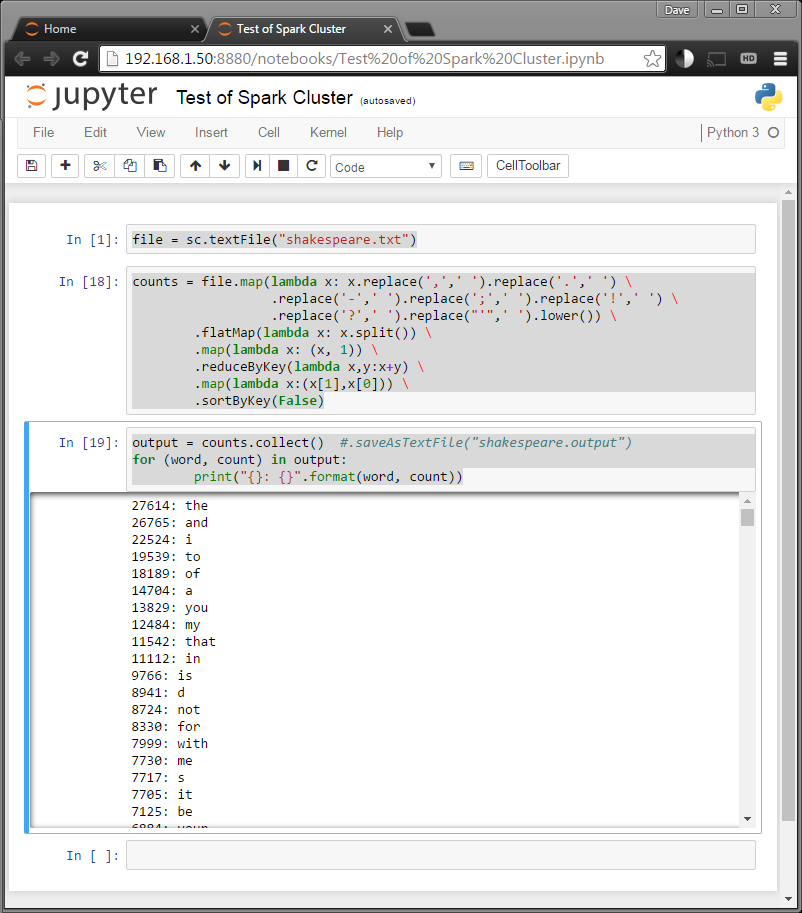
Make three inputs from the python below (Enter statements in the notebook cells and press Shift+Enter or Shift+Return to run.)
file = sc.textFile("shakespeare.txt")
***NOTE: Don’t forget to check out the auto-complete you get by hitting the TAB key mid way through typing “shakespeare.txt” Awesome!
counts = file.map(lambda x: x.replace(',',' ').replace('.',' ') \
.replace('-',' ').replace(';',' ').replace('!',' ') \
.replace('?',' ').replace("'",' ').lower()) \
.flatMap(lambda x: x.split()) \
.map(lambda x: (x, 1)) \
.reduceByKey(lambda x,y:x+y) \
.map(lambda x:(x[1],x[0])) \
.sortByKey(False)
output = counts.collect() #.saveAsTextFile("shakespeare.output")
for (word, count) in output:
print("{}: {}".format(word, count))
You should get a nice list of counts of the words Shakespeare was most fond of!